
Thoughts on Inference-time Compute
Published:
A. Pre-training vs. Inference-Time Compute
Before delving into inference-time compute, it is crucial to clarify the distinction between pre-training and inference-time compute:
Fine-Tuning operates under the assumption that “the LLM’s capabilities are not yet sufficient to adequately address certain problems.” This approach aims to improve the model’s underlying capabilities, enhancing its ability to solve these problems.
Inference-Time Compute, in contrast, assumes that “the LLM already possesses sufficient capabilities, but these are not being fully utilized.” This approach focuses on optimizing how the model’s existing capabilities are harnessed during inference to achieve better performance.
Let’s formalize the distinction between fine-tuning and inference-time compute:
\[y \sim P(x, G_{\theta})\]Where:
- x: the input, such as a question or query.
- G: the generator, representing the well-trained LLM.
- theta: the parameters of the LLM.
- y: the output generated by the LLM (e.g., the answer to the query).
- P(.): a broader concept encompassing not just a single inference pass through the LLM but also advanced inference-time techniques like Self-Consistency Chain-of-Thought (SC-CoT), Tree-of-Thoughts (ToT), Monte Carlo Tree Search (MCTS), and others.
The ultimate goal is to map x (input) to y (output).
- Fine-Tuning improves G by refining its parameters theta, thereby enhancing the LLM’s intrinsic performance across tasks.
- Inference-Time Compute focuses on improving P(.), the process of mapping x to y, by employing advanced reasoning and computation strategies during inference.
B. Why Does Inference-Time Compute Work, and What Problem Should We Solve?
To understand why inference-time compute works, consider the figure below:
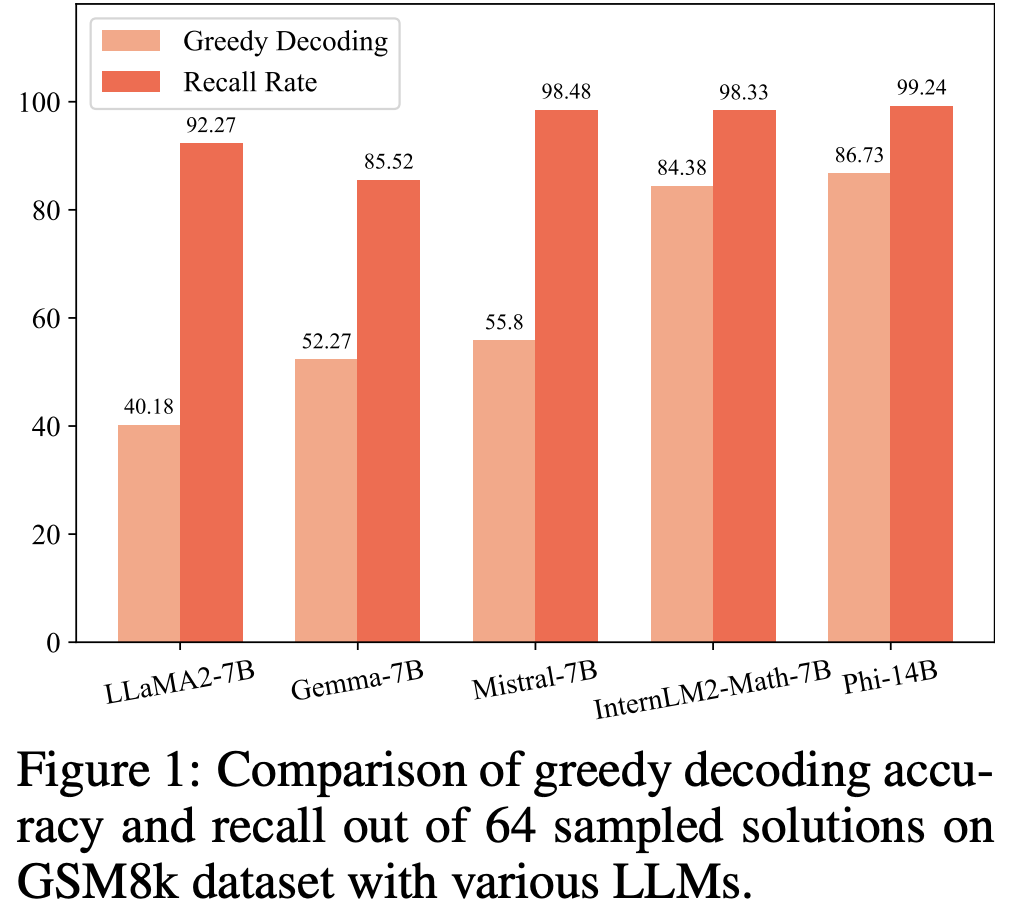
The data reveals a critical insight: when sampling answers from the model 64 times, the probability of obtaining at least one correct response exceeds 90%. This highlights a key point:
“The LLM has the capability to provide the correct answer to a problem.”
This aligns with the core motivation behind inference-time compute:
“The LLM’s capabilities are sufficient, but we are not fully utilizing them.”
If this premise were false, inference-time compute strategies would have limited impact.
The Real Problem
Despite the LLM’s ability (or knowledge) to produce the correct answer, it often fails to do so during greedy decoding. This limitation is inherent to probabilistic models like LLMs. Consequently, much of the ongoing work in inference-time compute focuses on bridging this gap between the LLM’s latent capabilities and its surface-level performance.
C. Inference-Time Compute Methodologies
1. Majority-Vote-Based Self-Consistent Chain-of-Thought (SC-CoT)
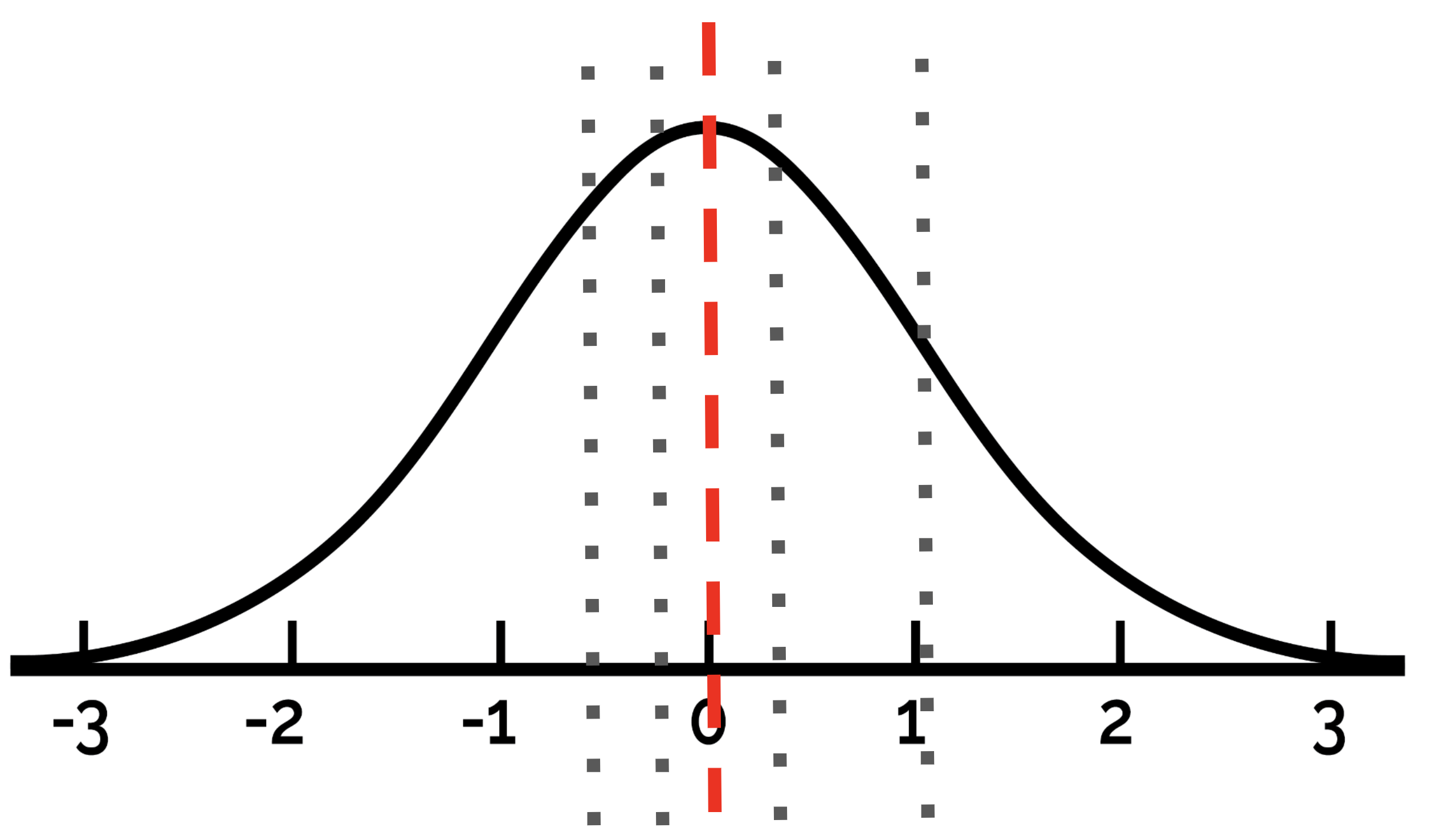
One straightforward inference-time strategy is Self-Consistent Chain-of-Thought (SC-CoT). This involves sampling multiple Chain-of-Thought (CoT) reasoning paths and using a majority vote to select the final answer. The premise of SC-CoT is:
“The more answers are sampled from an LLM, the closer those answers converge to what the LLM deems the most correct response.”
This concept is illustrated below:
However, SC-CoT alone is insufficient. The limitation lies in this critical observation:
“What the LLM considers the most correct answer is often not the actual correct answer.”
In many cases, the true answer resides not at the central mode of the LLM’s output distribution but at a less frequent, “minority” position within that distribution. This challenge is illustrated below:
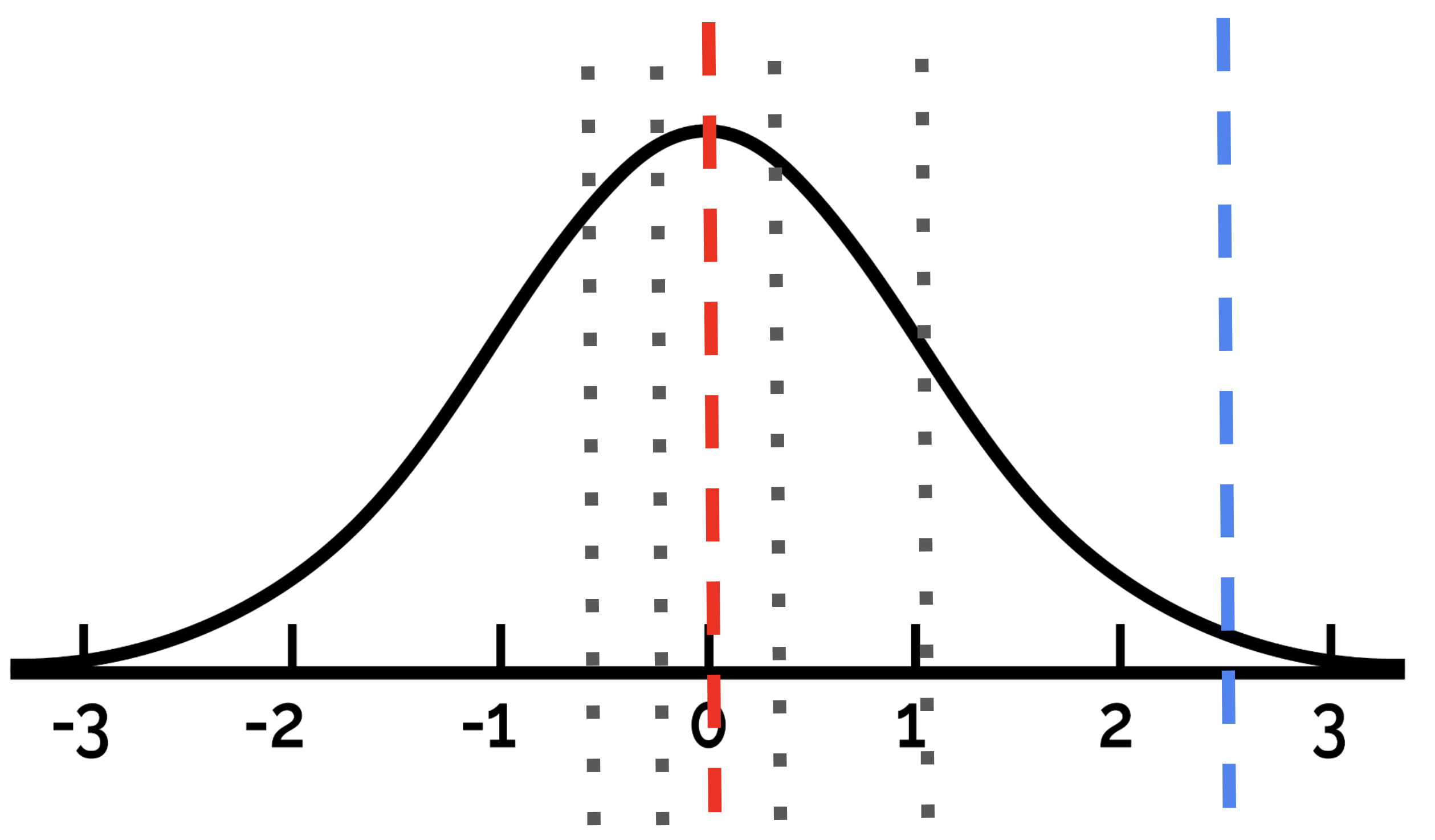
Addressing the Challenge: Introducing a Verifier
To overcome this limitation, a verifier is introduced. The verifier evaluates the correctness of each candidate answer using an external or secondary metric rather than relying solely on the LLM’s confidence.
By leveraging this additional evaluation layer, the verifier can identify the actual correct answer, even when it lies outside the majority predictions of the LLM.
2. Verifier-based Self-consistent CoT
The philosophy behind verifier-based SC-CoT can be summarized as:
“I, the generator, have produced multiple potential answers, but I don’t know which one is correct. So I’ll delegate this decision-making process to the verifier.”
In this setup, one LLM focuses exclusively on answer generation, while another takes on the role of verification. This can be seen as a kind of dual-agent system, where the generator creates diverse outputs, and the verifier evaluates their validity.
For further details, we can check the let’s verify step by step paper, but I’ll not delve into its detail for now.
3. Tree of Thoughts (ToT) & MCTS
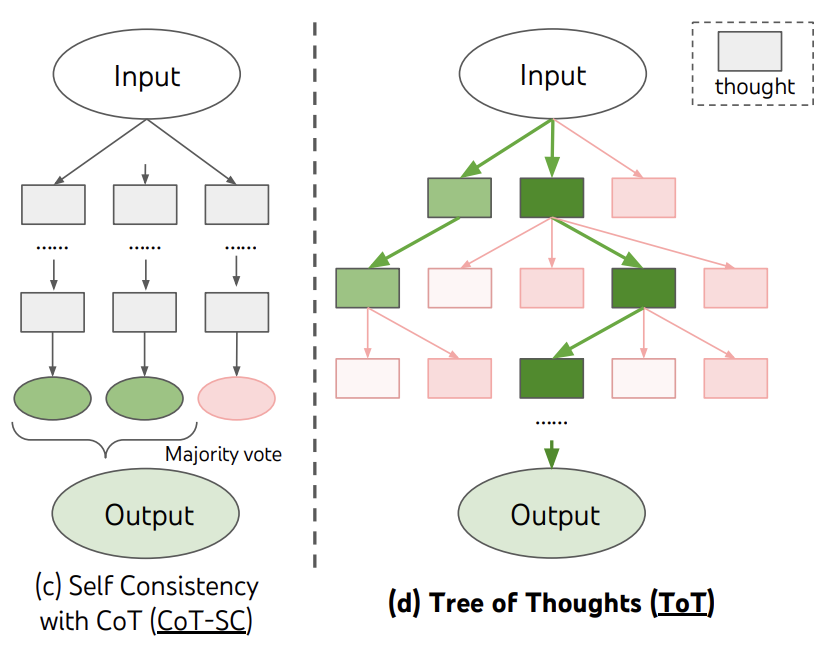
SC-CoT and ToT are fundamentally similar, with the primary distinction being efficiency. In ToT, intermediate steps with low scores are pruned rather than developed further, making it more computationally efficient. This approach is reminiscent of how AlphaGo conserves computational resources by focusing only on high-scoring moves instead of exploring every possible scenario.
Building on this idea is Monte Carlo Tree Search (MCTS). What sets MCTS-based methodologies apart from vanilla ToT is their ability to recursively train both the generator (or actor) and the verifier (or critic) in tandem. This recursive feedback loop allows for more sophisticated decision-making and improved performance.
A concrete example of this approach is detailed in the ReST-MCTS paper, which demonstrates how MCTS can be leveraged to enhance inference-time reasoning and optimization.
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
To summarize, the evolution of inference-time compute methodologies can be outlined as follows:
- SC-CoT with Majority Vote: As more answers are sampled from the LLM, they tend to converge toward what the LLM considers the most correct response. Thus, the strategy is to sample multiple answers and select the final output via majority vote.
- SC-CoT with Reward Models: The actual correct answer often lies outside the central mode of the LLM’s distribution. To address this, a reward model is trained to identify and prioritize these less frequent but correct answers.
- ToT & MCTS: Expanding low-reward intermediate steps is inefficient. Instead, Monte Carlo Tree Search (MCTS) focuses computational resources on the most promising traces, targeting paths with the highest probabilities of success.
D. Some Thoughts
This section isn’t about explaining what I understand but rather raising questions about areas
1. SC-CoT vs. MCTS
I first became interested in inference-time compute methodologies following the release of OpenAI’s o1, which delivered performance far surpassing GPT-4o. The o1 model made a significant impact, and upon reverse-engineering it, we tentatively concluded that it was based on an MCTS framework.
However, this raises a question: does MCTS truly deliver overwhelmingly superior performance over other methodologies? I’m inclined to think the answer might be no.
As I previously explained, MCTS can essentially be viewed as a more efficient version of SC-CoT with PRM. While it enhances efficiency, the performance ceiling of MCTS and SC-CoT remains the same, assuming sufficient computational resources. This is evident in the *ReST-MCTS** paper, which we reviewed previously. If you recall, the performance of the MCTS algorithm didn’t show a substantial improvement over SC-CoT or other inference-time compute methodologies (see the referenced figure below).

The reason I bring this up is to emphasize that MCTS is NOT a completely new paradigm—it is an extension of SC-CoT with PRM. While it’s important to acknowledge the potential of MCTS, I think we should be cautious about attributing excessive credit to it.
2. What Makes o1 So Effective?
The foundation of o1 is MCTS. However, can we attribute its success solely to the integration of MCTS into an existing model like GPT-4o without any other changes? I don’t believe so. There must be additional factors at play. Two possible elements come to mind:
- Fine-tuning the LLM
- It’s possible that the base LLM used in o1 was fine-tuned specifically for reasoning tasks or even trained from scratch on a specialized dataset.
- While reviewing EMNLP 2024 papers in the past two days, I came across a study titled Distilling System 2 to System 1 (link). Given that o1’s outputs often include phrases like “hmmm” or “alternatively,” it seems likely that the LLM in o1 underwent similar training methods to enhance its reasoning capabilities.
- Additionally, techniques such as discrete action spaces or specialized “thinking modules”—mentioned in previous discussions—could also have been incorporated into the LLM used in o1.
- Quality of PRM
- The PRM is a critical component, as it serves to identify the correct reasoning trace. Thus, whether MCTS or SC-CoT is used, the quality of the PRM is pivotal.
- According to the Let’s Verify Step-by-Step paper, OpenAI appears to have developed its PRM by collecting extensive human-annotated data, which could have significantly improved the PRM’s effectiveness.
- Furthermore, automation methods like those in the Math-Shepherd paper may have been employed to train the PRM, further refining its ability to evaluate reasoning steps.
There will be some other factors too, but I can think of these two only for now.
3. Research Directions Related to o1
Inference-time compute is undoubtedly the next paradigm in the LLM field, and conducting research in this area is indeed fascinating. However, we must consider our computational resources. The essence of methodologies like MCTS and SC-CoT is that performance improves with scaling at inference time, making them computationally demanding. Therefore, it’s prudent to focus on areas within our capabilities.
Currently, I am considering the following research topics:
- Enhancing PRM Model Performance
- I am still unclear about why PRMs function effectively. Mapping a process to a specific value seems straightforward, yet its success is intriguing. Delving deeper into this could uncover valuable research opportunities.
- Additionally, I reviewed the paper Process Reward Model with Q-Value Rankings published three days ago. Exploring ways to improve PRM automation algorithms, as discussed in this paper, could be a promising research direction.
- Fine-Tuning LLMs
- An idea mentioned during discussions on MCTS involves collecting data through a “self-correction” process by performing DFS on trees generated during MCTS and then using this data for fine-tuning. Recently, Meta published a paper titled Distilling System 2 into System 1, which attempted this approach and achieved notable performance improvements.
- Others..